
The core of Qwen 3.5 is the GDN linear attention structure, but the GDN structure is complex, and the selection of operators and the access scheme are also quite complicated. This article shares the practice of quickly accessing high-performance operators on the Ascend NPU, including the CANN environment setup, custom operator compilation, and more.PyTorchExamples of adaptation and operator integration. The operators mentioned in the article have been merged into the latest version of vLLM.
Qwen3.5 Introduction
Qwen3.5 is a native multimodal large model released in February 2026. This series adopts andQwen-Next’s consistent hybrid architecture incorporates both linear and traditional attention. It achieves high performance on long sequences while maintaining model performance equivalent to traditional attention . Qwen3.5 outperforms GPT-5.2 and [other models/components] in multiple benchmark tests, including MMLU-Pro and IFBench.GeminiThe Qwen 3 Pro supports up to 2 hours of video understanding and autonomous operation of computers and mobile phones, among other intelligent agent capabilities. The subsequent release, Qwen 3.5-Omni, achieved native full-modality capabilities, reaching state-of-the-art performance in 215 tasks.
As of today, Qwen 3.6 has also been released, but the model structure has not undergone major changes. The experience described in this article is applicable to Qwen 3.6 users as well.
Model Highlights
The model structure of the flagship version Qwen3.5-397B is shown in the figure:
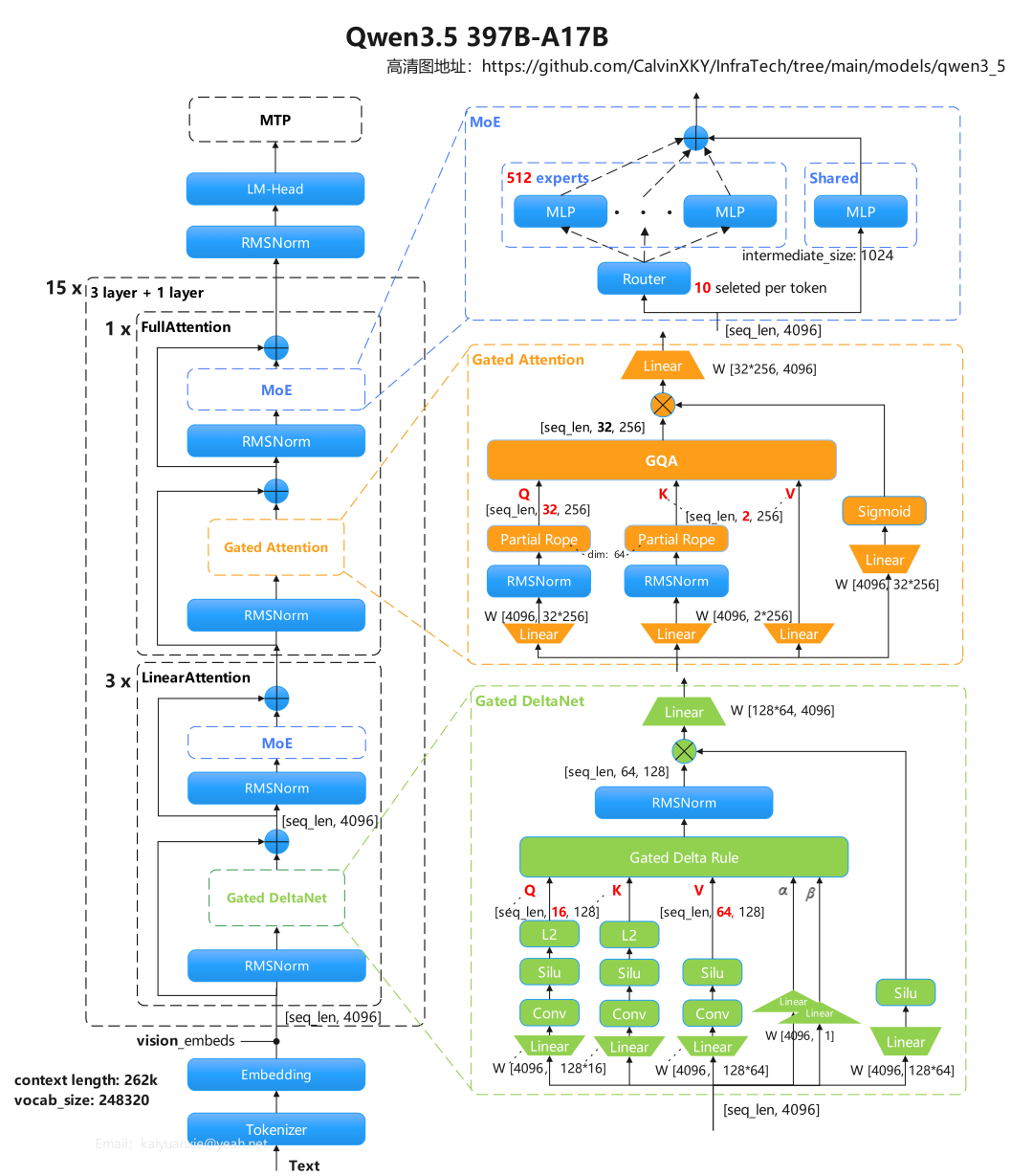
Qwen3.5 uses a 4-layer cycle, with each cycle containing one traditional non-linear layer and three linear layers. The distinction between non-linear and linear layers lies only in the Attention module; the FFN module is identical. The specific number of layers and the choice of FFN (including Dense and Moe ) may vary depending on the model’s minor version.
The linear layer transforms traditional non-linear attention into linear attention, breaking the O(n²) complexity for long sequences. It employs linear attention…algorithmIt is the industry’s leading Gated Delta Net (GDN), which combines the Mamba and Delta Net algorithms, and can take into account global decay while establishing the logic of single key value replacement.
The FFN layer adopts the classic MOE structure, with as many as 512 experts. The experts are small, and the hidden size of the middle layer is only 1024. Each token selects 10 routing experts and one shared expert, conforming to the current trend of multiple small expert configurations. The selection algorithm for the 10 routing experts is a simple Topk algorithm, without evolving new routing strategies.
In summary, the impact of Qwen 3.5 on the NPU is concentrated in the GDN of the Attention module, which is also the most difficult part of out-of-the-box operator adaptation. To address this pain point, this article provides a guide to high-performance operator integration. The following sections will focus on GDN, while also briefly introducing operator selection for the FFN module.
The operators in this article have been merged.vLLMLatest version and enabled, version link:
https://quay.io/repository/ascendThe operators in this article are included in both version 0.20 and the latest main version, /vllm-ascend?tab=tags&tag=latest.
Quick Enable Guide
The diagram below simplifies the replacement logic for the complex GDN, MOE, and fusion operators (not all interfaces are listed in the diagram).
For GDN operators, the preprocessing operator Causal_conv1D and the six GDN fusion operators need to be replaced. For MOE operators, apart from a simple fusion replacement in GmmSwigluQuant, the most worthwhile high-performance interface to switch is Dispatch/Combine.
CANN Development Environment Deployment
First, you need to install the CANN development kit, which provides the underlying drivers and toolchain required for NPU operators to run.
Community edition 8.5.2 is recommended. You will need to download two run packages. Here, we’ll use an A3 machine as an example (i.e., you need to download A3-ops and toolkit).
The download address is [ link to download].
The link https://www.hiascend.com/developer/download/community/result?module=cann&cann=8.5.2
requires you to find the package corresponding to your current machine.
Set the installation path
export INSTALL_PATH=/usr/local/Ascend
./Ascend-cann-toolkitrun –install-path=$INSTALL_PATH –full –quiet ./Ascend-cann-A3run –install-path=$INSTALL_PATH –install –quiet
source $INSTALL_PATH/ascend-toolkit/set_env.sh
Compile custom operator packages
Next, you need to install the operator package that includes high-performance GDN operators. Here, you’ll need to use the third-party library fla-npu.
The download address is
https://github.com/flashserve/flash-linear-attention-npu
Compilation command, note that –soc=${soc_version} needs to be specified as the chip type of the current machine.
bash build.sh –soc=ascend910_93 –pkg –ops=chunk_bwd_dv_local,chunk_bwd_dqkwg,chunk_gated_delta_rule_bwd_dhu,prepare_wy_repr_bwd_da,prepare_wy_repr_bwd_full,chunk_fwd_o,chunk_gated_delta_rule_fwd_h,recurrent_gated_delta_rule,recompute_wu_fwd
Install run package
./build_out/cann-ops-transformer-custom_linux-aarch64.run
torch_custom framework compilation and building
Download and install the latest distribution for your Python and Torch versions.
https://gitcode.com/Ascend/pytorch/releases/
requires version 26.1 beta or later.
Compile and install the torch adapter whl package
cd torch_custom/fla_npu
bash build.sh
Operator access
Qwen3.5 involves many operators. We will not go into detail about the non-linear layers based on traditional Attention and the mature operators with a relatively small proportion of the overall network time consumption. We will only explain the medium and heavy operators under the new structure.
List of key operators
Inference – Prefill Scene / Training – Forward Scene
The inference prefill uses the same operators as the training forward feed, involving a total of 7 fusion operators, as shown in the table below:
Reasoning-Decode Scenarios
Training – Reverse Scenario
The reverse scenario contains many forward operators; here we will only mention the operators involved only in the reverse process.
Attention Module – GDN Integration Practice
Before integrating GDN operators, let me explain some design considerations we made in pursuit of ultimate performance. To obtain the full performance benefits, there are two things to keep in mind when integrating GDN operators.
The default tensor layouts passed in the model are fixed-length BSH and variable-length TND. For GDN, read and write operations will cross high N dimensions, leading to reduced memory access efficiency. Since there are many GDN operators, the overhead of transpose is less than the cost of reduced memory access efficiency. Therefore, this article recommends using special layouts of NTD or BNSD for all GDN operators. To reduce the transpose overhead introduced by such layouts, we perform the conversion from the default layout to the special layout in the forward and backward iterations of the GDN preprocessing operator causal_conv1D. All GDN operators use the same special layout, and there is no layout change during the GDN process.
To achieve better tiling and more rigorous load balancing, the host phase of the Ascend C operator should obtain cu_seqlen, which also helps us intercept some indexing errors. Therefore, the input cu_seqlens of the Ascend C GDN operator is a list (on the host), while the Triton GDN operator uses tensors (on the device). The physical meaning of cu_seqlen is batch logic, which means that all GDN operators in the 45 linear layers require the same input. We need to store one copy on both the device and the host from the beginning, so that h2d is performed only once in each training step or each complete prefill task.
FFN Module – Dispatch/Combine Integration Practice
The Dispatch and Combine operators replace the AllToAllV communication operator in the Moe layer. The AllToAllV communication operator involves H/D synchronization, resulting in long processing times. After replacing it with Dispatch and Combine, the processing of expert routing results is decentralized to the Device, eliminating the host and device synchronization overhead. After several iterations of evolution, the Dispatch and Combine operators utilize AIV-driven ROCE capabilities and are further optimized with communication data deduplication, intra-machine and inter-machine pipelined parallelism, etc. In typical scenarios, the model throughput performance is improved by 50%.
The input of the Dispatch and Combine operators is relatively simple. The model only needs to take the data x and the top k expert indices expert_ids selected by the previous gating network as input, and provide attributes such as the number of Moe experts moe_expert_num, the EP communication domain size ep_world_size, and rank ID. The Dispatch output data expand_x and the number of tokens for each expert expert expert_token_nums are directly provided to the subsequent GMM. The auxiliary information related to the communication algorithm, assist_info_for_combine, is directly passed through to Combine from the Dispatch output; the model does not need to be aware of it.
For detailed explanations of the operator interface parameters and calling examples, please refer to the interface documentation.
Dispatch:
https://www.hiascend.com/document/detail/en/Pytorch/2600/apiref/torchnpuCustomsapi/docs/zh/custom_APIs/torch_npu/torch_npu-npu_moe_distribute_dispatch_v2.md
Combine:
https://www.hiascend.com/document/detail/en/Pytorch/2600/apiref/torchnpuCustomsapi/docs/en/custom_APIs/torch_npu/torch_npu-npu_moe_distribute_combine_v2.md
Optimization results
In scenarios with input size bs=64, seqlen=1k, and num_head=32, the optimization effects of key GDN operators are as follows:
The average execution time is reduced to 44% of the original Triton operator .
In a scenario with an input size of ep64, bs=32, seqlen=1, hiddensize=7k, and topk=8, the optimization effect of the Dispatch/Combine operator is as follows:
The average processing time was reduced to 43 % of the baseline method .
