Injecting Self-Evolutionary Genes into Huawei Cloud Code-Based Intelligent Agents: Preliminary Exploration and Practice of Skill Self-Iterative Optimization Technology
In the context of programmable intelligent agents , Skills are gradually becoming the means of connection.ModelSkills are a key vehicle for capabilities and real-world R&D tasks. Compared to one-time Prompt calls, Skills can accumulate task experience, reuse execution strategies, and significantly improve the stability and execution quality of agents in complex engineering tasks such as unit test generation, code modification, and bug fixing. Therefore, whether Skills possess continuous optimization capabilities is becoming one of the important factors determining the continuous evolution of the capabilities of programming intelligent agents.
Recently, there has been a lot of exploration in the industry regarding the self-iteration, self-evolution, and continuous learning of skills. The focus has gradually shifted from “how to build a skill” to “how to make the skill continuously optimize and play a stable role in real tasks.”
To address this issue, Huawei Cloud’s CodePath Intelligent Agent explored a skill self-iterative optimization mechanism. This mechanism enables the CodePath Intelligent Agent to continuously generate, verify, evaluate, and optimize skills based on real-world task results and further attempts to drive skill evolution with objective task metrics. In real-world business code repository unit test completion practice, this method improved line coverage from 46% to 96.61%, branch coverage from 33.8% to 83.8%, and function coverage from 37.5% to 100%, validating the technical value of skill self-iteration in real-world R&D scenarios.
Industry Technology Insights: Skill Self-Evolution Technology
In the past, the main competitive advantages of programming intelligent agent systems have focused more on basic model capabilities, tool integration capabilities, context length Regarding task orchestration capabilities, however, as real-world R&D scenarios continuously lengthen task chains, increasing research and engineering practices are showing that what truly determines the long-term performance ceiling of a programming agent is no longer just “whether a single task can be done well,” but rather whether the system can distill the effective practices accumulated from repeated tasks into reusable, updatable, and transferable capability assets. Recent systematic reviews on Agent Skills also clearly indicate that Skills are evolving from one-off prompts to enhanced or… The tool call encapsulation has gradually evolved into an important intermediate layer that carries procedural knowledge and supports long-term capability accumulation [1].
This trend has been quite evident in recent representative studies. The core idea of AutoSkill [2] is to automatically extract, maintain, and reuse skills from real interaction trajectories, transforming the interaction experience that is easy to dissipate with the end of the task into explicit, maintainable, and transferable capability assets, and this process does not rely on retraining the underlying model. XSkill[3] further breaks down reusable knowledge into two layers: “experience” and “skills,” forming a continuous learning loop based on multi-path rollout, induction and retrieval adaptation, and achieving stable improvement under multiple benchmarks and different backbone settings.
If the above work emphasizes “how to precipitate experience into skills,” then methods like SkillRL [4] have begun to further advance the evolution of skills to the stage of “continuous experimentation and optimization around the objective function.” Its core idea is to allow the Agent to continuously propose modifications, execute experiments, obtain feedback based on the results within a fixed budget, and directly convert the task results into subsequent optimization signals. At the same time, the Skill Creator [5] update released by Anthropic in 2026 has also advanced skill development from “writing a skill” to an engineering closed loop of “writing tests, running evaluations, comparing new and old versions, and continuously rewriting and optimizing around real tasks”; a key signal reflected behind this is that skill optimization is shifting from experience-driven to evidence-driven.
Looking at these studies and engineering practices together, a clearer direction emerges: the competition among high-level programming agents will no longer be about “whether they can use tools,” but rather “whether they can transform experience into skills and continuously evolve those skills.” In other words, programming agents are shifting from “task execution systems” to “capability growth systems.” In this process, skills are no longer merely auxiliary modules but are becoming a crucial intermediate layer connecting experience accumulation, task verification, and continuous optimization. Simultaneously, the harness design on the engineering side is increasingly proving to directly impact the stable performance of this capability.
From Automated Development to Continuous Optimization: Technological Exploration and Practical Results
2.1 Skill Self-Iterative Pipeline Based on Systematic Evaluation Technology
This current skill self-iterative pipeline for puncture scenarios has initially formed a relatively complete closed-loop structure, which can be broken down into four interconnected core units: intent capture, skill writing and verification, skill evaluation, and iterative optimization. Compared to the traditional method that relies on manual debugging, this pipeline emphasizes enabling the agent to complete the entire closed loop from requirement understanding to capability evolution in real-world tasks, compressing the originally scattered analysis, development, verification, and improvement processes into a continuously running automated chain.
First is the intent capture module. This module is primarily responsible for summarizing and structuring the input task information, transforming the originally scattered and unstructured requirements into task definitions that can be directly consumed in subsequent optimization processes. Through this process, the system will generate three key products: one is a summary of the current task’s capability boundaries and objectives, i.e., the skill requirement itself; another is quantitative indicators for measuring performance; and the third is the examples upon which training and evaluation rely. These three products establish a unified starting point for the subsequent writing, verification, and iteration of Skills.
The skill writing and verification module serves to generate capabilities and verify effects. On one hand, the Agent needs to continuously iterate on Skills under defined task constraints; on the other hand, it also needs to compare and quantify the execution of new and old versions under a unified standard. To ensure the reliability of the comparison results, the system evaluates different versions of Skills independently, fully preserving the execution process and final results as a basis for subsequent analysis. Simultaneously, the system generates more user-centric descriptions of expected outcomes based on specific tasks, ensuring that the verification process goes beyond simple output comparisons and addresses “what kind of process and results the user truly wants to see.”
The core function of the skill evaluation module is to transform the execution records accumulated in the previous stage into quantifiable and interpretable feedback signals. The system analyzes the performance of skills on different examples, considering task expectations, to determine whether the expected goals were truly achieved and then calculates the overall achievement. Compared to evaluation methods that only focus on the final score, this design emphasizes evidence-driven approaches: it considers both the correctness of the result and whether the process meets expectations. Based on these analyses, the system can further determine whether the current skill iteration has achieved substantial improvements compared to previous versions and automatically generate feedback information for the next round of optimization.
Finally
There’s the iterative optimization module. This module takes the evaluation results and transforms the effective experiences and failure modes exposed in the previous round of analysis into the basis for the next round of skill updates. In other words, the system doesn’t stop after one validation but continues to adjust and optimize the skill based on feedback, driving it into a state of continuous evolution. Thus, the entire process forms a complete closed loop: starting from understanding requirements, through skill generation and validation, then to effective evaluation and feedback, ultimately achieving continuous optimization for real-world tasks.
Overall
These four modules together form a relatively complete skill self-evolution chain: the front end is responsible for compressing unstructured requirements into structured problem definitions; the middle section is responsible for generating capabilities and verifying them under unified constraints; and the back end drives the skill through evidence-based evaluation and feedback loops, pushing it into multiple rounds of optimization. It attempts to solve not just “how to generate a usable skill” but “how to continuously validate, correct, and accumulate skills in real-world tasks.” Compared to one-time prompt projects or manual rule tuning, this design is closer to a viable development closed loop and aligns more closely with the industry’s mainstream understanding of “continuous learning, continuous evaluation, and continuous improvement” for agent systems in recent years.
Currently
This pipeline is performing puncture tests on the code path, achieving good results on some basic skills, and is already capable of initially iterating on some fundamental tasks in the skill development process. For unit test generation, Huawei Cloud CodePath Intelligent Agent extracted the tested functions from open-source projects and compared the following: a. Skill-independent; b. Skill generation using this method for self-iterative unit test generation; c. Skill generation from manually tuned unit tests. The results show that the automatically iteratively generated skills improve line coverage, test pass rate, and assertion validity by 90%, 66%, and 80%, respectively, achieving results comparable to manually tuned skills. A demonstration video below showcases the effectiveness of the Skill self-iterative technology in unit test generation scenarios.
Recently, Huawei Cloud’s CodePath Intelligent Agent has been used to practically verify this technology in a real-world business scenario (intelligent generation of unit test cases). Unit tests were added to a moderately complex business code file (approximately 680 lines of code, 15 functions, involving patch parsing, file operations, pattern matching, and other technologies) in a TypeScript code repository. The complexity of this file is mainly reflected in implementing complete patch parsing and application functions, including support for three operation types, a file content replacement algorithm, multi-strategy pattern matching, and file system operations; it also includes a complex parsing state machine, numerous error handling branches, and recursive/iterative data processing logic.
Test results show that after generating unit tests using the self-iteratively generated UT Skill in the code path, compared with the baseline version without the Skill, all coverage metrics are significantly improved: line coverage increased from 46% (319/680) to 96.61% (657/680), branch coverage increased from 33.8% (48/142) to 83.8% (119/142), and function coverage increased dramatically from 37.5% (6/16) to 100% (16/16). This practical result fully verifies that the skill self-iterative technology can effectively improve the coverage quality and code logic comprehension of unit tests in real business code scenarios.
2.2 Skill Self-Iterative Exploration Based on Evolutionary Algorithm
In the Skill automatic optimization pipeline introduced in section 2.1, Huawei Cloud CodePath Intelligent Agent has attempted to replace manual or… AI This involves purely qualitative judgment to quantitatively evaluate the effectiveness of skill iterations. Compared to traditional methods that rely on subjective experience, this step provides a measurable and comparable closed-loop foundation for skill optimization. Simultaneously, the system also introduces auxiliary scripts to perform more stable analysis of some result metrics, such as compilation rate, to improve the consistency of the evaluation.
However, this approach also has significant limitations:
while it achieves quantitative evaluation, the overall granularity remains coarse, and core judgments still largely rely on AI for autonomous processing. For the automatic evolution of skills truly geared towards production environments and high-availability scenarios, this semi-structured evaluation method alone is insufficient. A more crucial direction is to base the optimization process on objective, stable, and reproducible task metrics as much as possible. This aligns with recent research observations on the real-world effectiveness of skills: only when skill retrieval, selection, adaptation, and refinement can truly and consistently contribute to task results can a skill move from “seemingly useful” to “reliably useful in production.”
To address the aforementioned limitations, Huawei Cloud CodePath Intelligent Agent further explored an automated skill evolution pipeline driven entirely by objective task metrics in unit testing scenarios. This solution continues the environment isolation approach from section 2.1, ensuring fair and controllable execution and comparison of different skill versions. However, in the evaluation phase, it no longer primarily relies on AI to interpret the expected achievement; instead, it directly constructs optimization goals around the task results. During the puncture phase, Huawei Cloud CodePath Intelligent Agent defines four core metrics: compilation rate, Pass@1, average number of compilation errors, and average repair time. The system evaluates the overall performance of the current round of skill based on the weighted scores of these four metrics, thus determining in a more objective way whether the skill has truly improved.
During the iteration phase, the system no longer simply makes localized modifications based on single-round feedback. Instead, it provides the agent with copies of each skill iteration and their evaluation performance, allowing the agent to analyze the effective factors in different versions and further combine them to form stronger skills. Compared to the previous approach, this pipeline places greater emphasis on driving skill evolution with task results as the core, providing a more solid foundation for the automatic evolution of skills from “usable” to “production-ready.”
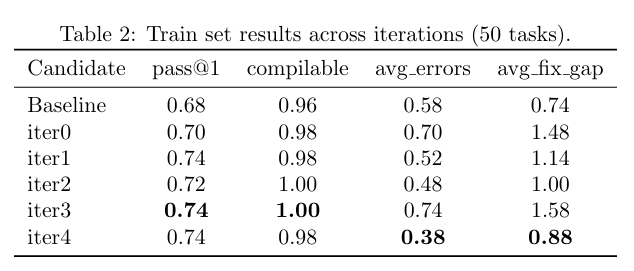
Huawei Cloud CodePath Intelligent Agent carefully evaluated the performance of this method on a training set consisting of 50 tested methods. It can be seen that with the increase of training, both the average number of errors (avg_errors) and the average fix distance (avg_fix_gap) have improved.
III. Future Work Outlook
Overall, future work can focus on two main directions.
First, there’s the issue of generalization validation for real-world R&D scenarios. While the current automatic skill evolution has demonstrated clear benefits on specific tasks and local samples, whether these benefits can stably transfer to unseen tasks, different codebases, different technology stacks, and more complex engineering constraints still requires further verification. Going forward, we need to build an evaluation set covering more task types, more real-world repositories, and more difficulty levels to more accurately determine the boundaries of the benefits brought by skill evolution and prevent the system from only achieving improvements on localized data.
Secondly, the focus should shift from single-point skill optimization to harness engineering, which aims at a closed-loop operational model. Subsequent optimizations should not solely focus on the skill itself but should extend to the entire operational framework, including skill triggering methods, retrieval strategies, evaluation mechanisms, regression verification, failure recovery, and long-chain execution constraints. Recent public engineering practices at Anthropic have increasingly demonstrated that the effectiveness of agents in long-running tasks and complex software engineering scenarios highly depends on harness design, including mechanisms such as task decomposition, checkpointing, context compression, regression checking, and environmental stability control. For agent development, a more valuable future direction is to combine skill optimization with operational mechanism optimization, enabling the system to not only “possess better skills” but also “have an engineering framework that allows skills to function stably,” thereby driving the automatic evolution of skills towards true production-ready deployment.
References
[1] Jiang Y, Li D, Deng H, et al. SoK: Agentic Skills—Beyond Tool Use in LLM Agents[J/OL]. arXiv preprint arXiv:2602.20867, 2026.
[2] Yang Y, Li J, Pan Q, et al. AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution[J/OL]. arXiv preprint arXiv:2603.01145, 2026.
[3] Jiang G, Su Z, Qu X, Fung Y
R. Zhou Y, Zhao X, Chen H, Zheng Z, Xie C, Yao H. SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning[J/OL]. arXiv preprint arXiv:2602.08234, 2026.
[5] Anthropic. Skill Creator[EB/OL]. anthropics/skills repository, 2026.
